✅ DTO와 도메인의 변환
DTO를 사용하는 이유?
Although the main reason for using a Data Transfer Object is to batch up what would be multiple remote calls into a single call, it's worth mentioning that another advantage is to encapsulate the serialization mechanism for transferring data over the wire. By encapsulating the serialization like this, the DTOs keep this logic out of the rest of the code and also provide a clear point to change serialization should you wish.
https://martinfowler.com/eaaCatalog/dataTransferObject.html
- 한 번의 호출에 여러 개의 정보를 담을 수 있다. 따라서 네트워크 오버헤드를 줄여준다.
- 데이터를 전송하기 위한 직렬화 메커니즘을 캡슐화한다. 따라서 변경에 용이하다.
With DTOs, we can build different views from our domain models, allowing us to create other representations of the same domain but optimizing them to the clients’ needs without affecting our domain design. Such flexibility is a powerful tool to solve complex problems.
https://www.baeldung.com/java-dto-pattern
- 도메인을 변경하지 않고, 하나의 도메인에서 다양한 뷰를 생성할 수 있다.
DTO → 도메인 변환은 누가 담당해야 하는가?
레이어드 아키텍처에서 컨트롤러에서 받은 DTO를 서비스에서 변환해서 사용하곤 한다.
(살짝 다른 얘기로 조사하다가 DTO의 변환을 어느 계층에서 담당할 지에 관한 포스팅을 발견했다.)
그렇다면 변환이라는 행위는 어느 객체가 담당하는 게 적합할까?
1. DTO
public class DTO {
public Domain toDomain() {
// 변환 로직
return domain;
}
}DTO에서 도메인을 의존하게 된다.
- DTO에서 도메인을 변경할 위험이 있다.
2. 도메인
public class Domain {
public static Domain from(DTO dto) {
// 변환 로직
return domain;
}
}도메인에서 DTO를 의존하게 된다.
- 도메인이 다른 객체, 그것도 외부 세계에서 넘어온 객체를 의존하게 된다.
- 도메인이 두꺼워진다.
3. 서비스 (두 객체의 바깥)
public class Service {
public void method(DTO dto) {
Domain domain = new Domain(dto.getter());
}
}도메인과 DTO가 서로를 의존하지 않는다.
- 여러 서비스에서 변환이 일어날 경우 중복 코드가 많아져 관리가 어렵다.
4. mapper 객체
public class Service {
private final Mapper mapper;
public void method(DTO dto) {
Domain domain = mapper.map(dto);
}
}- 3번에 비해 서비스의 책임이 줄어들면서, 도메인과 DTO가 여전히 서로를 의존하지 않는다.
- Baeldung 사이트(https://www.baeldung.com/java-dto-pattern)에서는 DTO 패턴으로 소개한다.
- 객체를 새로 생성하기 때문에 작은 규모의 프로젝트에서는 부적절할 수 있다.
정답이 없는 걸 알고는 있었지만...
이에 관해 검색하던 중 다음과 같은 의견을 발견했다.
Keeping the mapping logic inside of your entity means that your Domain Object is now aware of an "implementation detail" that it doesn't need to know about. Generally, a DTO is your gateway to the outside world (either from an incoming request or via a read from an external service/database). Since the entity is part of your Business Logic, it's probably best to keep those details outside of the entity.
Instead of creating a mapping service layer, I've had a lot of success keeping my mappings inside of my DTOs. Since DTOs always sit at the boundary of the application, they can be made aware of the Business Object and figure out how to map from/to them. Even when the number of mappings scales to a large amount it works cleanly. All the mappings are in one place and you don't have to manage a bunch of mapping services inside your Data Layer, Anticorruption Layer, or Presentation Layer. Instead, the mapping is just an implementation detail delegated to the DTO involved with the request/response. Since serializers generally only serialize properties and fields when sending it across the wire, you shouldn't run into any issues. Personally, I've found this the cleanest option and I can say, in my experience, it scales nicely on a large code base.
If the amount of mappings scales to an unreasonable amount (which has yet to happen to me in over 10 years) then you can always create a mapping class that lives close to your DTOs.
https://stackoverflow.com/a/56711057
- 도메인에서 DTO를 의존하는 것은 피해야 한다. DTO는 외부 세계에서 온 객체이며 도메인이 매핑에 대한 '구현 세부사항'을 알 필요가 없다.
- DTO 안에서 매핑을 하는 방식으로 성공적으로 개발을 하고 있다.
- DTO는 항상 어플리케이션의 경계에 위치하므로, 비즈니스 객체(도메인)을 인식하고 매핑하는 방법을 알 수 있다.
- 매핑 수가 많아지는 경우에도 깔끔하게 작동한다.
- 하지만 매핑의 양이 매우 많아진다면 DTO 가까이에 있는 매핑 클래스를 만들 수 있다.
그리고 같은 질문의 다른 댓글도 발견했다.
You do not want your DTO layer to be aware of or dependant on your domain layer. The advantage of mapping is that lower layers can easily be switched out by changing the mapping, or that modifications in the lower layer can be controler by changing the mapping. Let's say dtoA maps to domainObjectA today, but tomorrow the requirement is that it maps to domainObjectB. In your case you have to modify the DTO object, which is a big no-no. You've lost alot of benefits of the mapper.
- DTO에서 도메인을 의존하지 말아라.
- 매핑의 장점은 매핑을 변경해 하위 레이어를 쉽게 전환할 수 있거나 매핑을 변경해 하위 레이어의 수정 사항을 제어할 수 있는 것이다.
- 하지만 DTO에서 도메인을 의존하면 매퍼의 이점을 잃는다.
- 두 객체의 사이에 존재하는 mapper class를 생성해라.
현재로써는 첫번째 의견에 더 공감이 간다. 두번째 의견에서 든 예시(DTO가 의존하는 도메인이 변경될 경우)는 그저 DTO 내에서 새로운 매퍼를 만들면 되고, 그러면 '하위 레이어를 쉽게 전환할 수 있다'라는 장점을 유지하는 게 아닌가 싶다.
우선 작은 프로젝트에서는 DTO에서 매핑을 담당하게 하고, 큰 프로젝트에서는 매핑 클래스를 생성하는 것이 나을 것 같다는 결론을 내렸다. (아무 의견 환영합니다... 👐)
✅ 중첩 트랜잭션
흥미로운 포스팅: 응? 이게 왜 롤백되는거지?
예전에 OSIV 관련 포스팅을 작성하다가 발견한 포스팅(https://techblog.woowahan.com/2606/)이 있다.
트랜잭션 안에서 exception을 잡았는데도 불구하고 롤백이 된 게 문제 상황이다.
globalRollbackOnParticipationFailure
디버깅 과정에서 globalRollbackOnParticipationFailure 속성에 의해 롤백 여부가 결정되었다. 참여한 트랜잭션이 실패했을 때, 전역 롤백을 할지 여부를 결정하는 속성이다. 해당 속성에 대한 설명은 다음과 같다.
Default is "true": If a participating transaction (e.g. with PROPAGATION_REQUIRES or PROPAGATION_SUPPORTS encountering an existing transaction) fails, the transaction will be globally marked as rollback-only. The only possible outcome of such a transaction is a rollback: The transaction originator cannot make the transaction commit anymore.
Switch this to "false" to let the transaction originator make the rollback decision. If a participating transaction fails with an exception, the caller can still decide to continue with a different path within the transaction. However, note that this will only work as long as all participating resources are capable of continuing towards a transaction commit even after a data access failure: This is generally not the case for a Hibernate Session, for example; neither is it for a sequence of JDBC insert/update/delete operations.
Note:This flag only applies to an explicit rollback attempt for a subtransaction, typically caused by an exception thrown by a data access operation (where TransactionInterceptor will trigger a PlatformTransactionManager.rollback() call according to a rollback rule). If the flag is off, the caller can handle the exception and decide on a rollback, independent of the rollback rules of the subtransaction. This flag does, however, not apply to explicit setRollbackOnly calls on a TransactionStatus, which will always cause an eventual global rollback (as it might not throw an exception after the rollback-only call).
The recommended solution for handling failure of a subtransaction is a "nested transaction", where the global transaction can be rolled back to a savepoint taken at the beginning of the subtransaction. PROPAGATION_NESTED provides exactly those semantics; however, it will only work when nested transaction support is available. This is the case with DataSourceTransactionManager, but not with JtaTransactionManager.
(1) globalRollbackOnParticipationFailure = True
참여한 트랜잭션이 실패하는 경우 전체 트랜잭션에 rollback-only가 적용된다. 즉 전체 트랜잭션이 롤백된다. 시작 트랜잭션에서는 더 이상 트랜잭션을 커밋할 수 없다.
(2) globalRollbackOnParticipationFailure = false
참여한 트랜잭션이 실패하는 경우 시작 트랜잭션이 롤백 여부를 결정할 수 있다. 시작 트랜잭션의 롤백 규칙이 서브 트랜잭션의 롤백 규칙과 독립적으로 작동한다.
하지만 모든 참여 중인 리소스가 데이터에 접근하는 데 실패한 후에도 트랜잭션 커밋을 계속할 수 있는 경우에만 작동한다. (일반적으로 Hibernate Session의 경우에는 해당되지 않으며 JDBC insert/update/delete 작업의 경우에도 해당되지 않는다.)
서브 트랜잭션 실패를 처리하기 위한 권장 해결책은 '중첩 트랜잭션(PROPAGATION_NESTED)'이다. 해당 트랜잭션 속성은 서브 트랜잭션 시작 시점에서 저장점을 가져와 전체 트랜잭션을 해당 저장점으로 롤백할 수 있게 한다.
PROPAGATION_NESTED
Transaction Propagation :: Spring Framework
PROPAGATION_REQUIRES_NEW, in contrast to PROPAGATION_REQUIRED, always uses an independent physical transaction for each affected transaction scope, never participating in an existing transaction for an outer scope. In such an arrangement, the underlying re
docs.spring.io
PROPAGATION_NESTED는 하나의 물리적 트랜잭션 내에서 여러 저장점(savepoint)을 사용하여 동작하며, 따라서 부분 롤백을 허용한다. 이는 내부 트랜잭션 범위에서 롤백이 일어나도 외부 트랜잭션은 물리적 트랜잭션을 계속할 수 있음을 의미한다. 이 설정은 일반적으로 JDBC 저장점으로 매핑된다.
PROPAGATION_NESTED vs PROPAGATION_REQUIRES_NEW
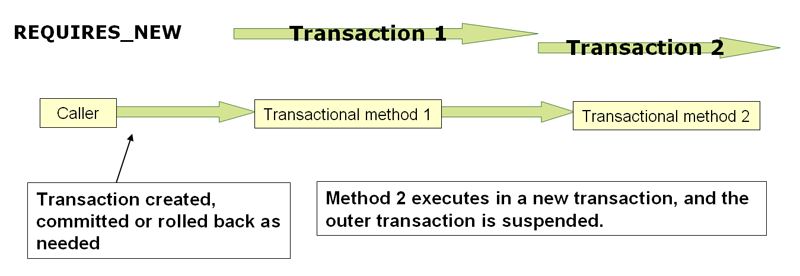
크게 물리적 트랜잭션의 개수 차이에 있다. REQUIRES_NEW로 호출 시 새 물리적 트랜잭션이 생성되지만, NESTED는 하나의 물리적 트랜잭션을 공유한다. 따라서 REQUIRES_NEW에서는 NESTED와 다르게 내부(엄밀히는 별개의) 트랜잭션이 외부 트랜잭션의 속성을 공유하지 않는다.
'개발일상 > TIL' 카테고리의 다른 글
| [230916] MySQL InnoDB의 베타 락 (2) | 2023.09.17 |
|---|---|
| [230914] Spring의 @Transactional 기본 설정, Spring의 AOP와 프록시, MySQL 아키텍처 (0) | 2023.09.14 |
| [230910] JPA에서 부모가 자식을 제한해서 가지는 경우 (4) | 2023.09.10 |
| [230907] Spring Boot 테스트의 롤백 (0) | 2023.09.08 |