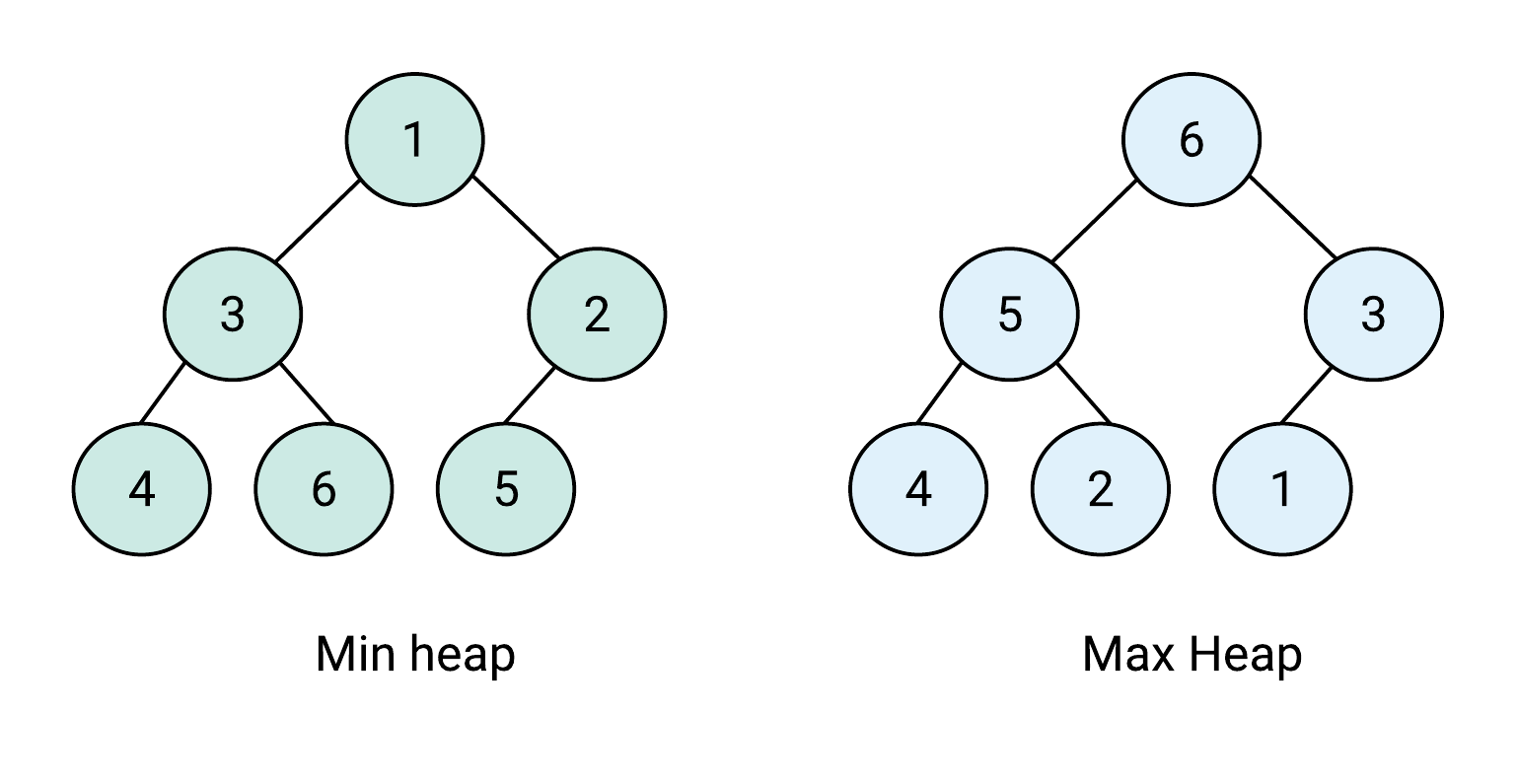
힙은 아래 속성을 만족하는 완전 이진 트리(complete binary tree) 기반 자료구조다.
최대 힙(max heap)에서 주어진 노드 C에 대해 P가 C의 부모 노드라면 P의 키(값)는 C의 키보다 크거나 같다.
최소 힙(min heap)에서는 P의 키가 C의 키보다 작거나 같다.
Sift Up 연산
힙에 노드를 추가할 때는 sift up 연산이 동작한다. 해당 연산은 리프 노드의 값으로 시작해 값을 위 노드의 값과 연속적으로 교환하여 값을 루트를 향해 경로 위로 이동한다. 위(부모) 노드와 비교해 트리의 속성을 만족할 때까지, 또는 루트 노드에 도달할 때까지 연산을 계속한다.
최소 힙에 노드(값 18)를 추가하는 과정
위 영상에서 새 노드(값 18)은 완전 이진 트리를 만족하기 위해, 최하단 자리 중 비어 있는 가장 왼쪽 자리에 추가되었다. 그리고 부모 노드(값 60)과 값을 비교한 후 최소 힙의 특성을 만족하기 위해 서로 자리를 변경했다. 이렇게 부모 노드가 자신보다 작은 값을 가질 때까지 위로 이동하므로 sift 'up' 연산이라고 한다.
이 연산은 최악의 경우 루트 노드까지 이동하므로 시간복잡도가 O(트리의 높이) = O(logN) 이 된다.
Sift Down 연산
반대로 힙에서 원소를 삭제할 때는 sift down 연산이 동작한다. 이름만 봐도 알겠지만, sift up 과 반대로 힙의 특성을 만족할 때까지 노드를 아래로 이동하는 연산이다.
이 연산 또한 최악의 경우 리프 노드까지 이동하므로 시간복잡도가 O(트리의 높이) = O(logN)이 된다.
힙 생성 (heapify)
그렇다면 무작위 값들이 담긴 배열로 힙을 생성해보자. 지금 예시에서는 최소 힙을 생성해보겠다.
첫번째 방식 - Sift Up 사용
우선 sift up 을 사용해 힙을 생성할 수 있다. 해당 연산이 하나의 노드를 힙에 추가할 때 쓰이므로, 비어있는 힙에 배열의 모든 값들을 순차적으로 추가하면 된다.
이 때 시간복잡도는 (1개의 노드가 있는 트리에 sift up) + (2개의 노드가 있는 트리에 sift up) + ... + (N개의 노드가 있는 트리에 sift up) 이므로 최악의 경우 O(log1 + log2 + ... + logN) = O(NlogN) 이 된다.
참고: O(log1 + log2 + ... + logN) = O(NlogN) 은 어떻게 성립하는가?
Stirling's approximation(링크)에 의하면 O(log1 + ... + logN) = O(log(N!)) = O(NlogN) 이 된다고 한다.
그렇구나...^^;
두번째 방식 - Sift Down 사용
sift down 연산을 이용해서도 힙을 생성할 수 있다. 이 때는 비어있는 힙에 노드를 순차적으로 삽입할 수 없다. (위에서 아래로 내려와야 하기 때문이다) 그래서 배열로 완전 이진 트리를 생성하고 마지막부터 순서대로 각 노드를 sift down 연산으로 움직인다.
이 때 시간복잡도는 높이가 고정된 트리에 대해 N번 연산을 수행하므로 N * O(logN) = O(NlogN)...이 아니다.
리프 노드를 생각해보자. 리프 노드에서는 sift down 연산을 수행하지 않는다. 내려갈 곳이 없기 때문이다. 다음으로 리프 노드의 부모 노드는 연산을 최대 1번만 수행할 것이다. 마지막으로 리프 노드만 최악의 경우 전체 높이만큼 이동하게 된다. 즉 각 노드의 높이에 따라 sift down 연산의 최대 실행 횟수가 달라진다.
따라서 시간복잡도는 높이 H에 대해 O(0 * (N/2) + (1 * (N/4)) + ... + (H * 1)) 이므로 O(N) 이 된다.
참고: O(0 * (N/2) + (1 * (N/4)) + ... + (H * 1)) = O(N) 은 어떻게 성립하는가?
Taylor series(테일러 급수)로 증명할 수 있다고 한다.
시간복잡도를 굳이 계산해보지 않아도, 트리 구조 상 아래로 갈수록 노드의 개수가 많아지기 때문에 sift up 보다는 sift down 이 빠를 것임을 추측할 수 있다.
그럼 실제로 자바에서 heap 으로 사용되는 PriorityQueue 클래스를 살펴보자.
class PrioirtyQueue {
public PriorityQueue(Collection<? extends E> c) {
if (c instanceof SortedSet<?>) {
// ...
}
else if (c instanceof PriorityQueue<?>) {
// ...
}
else {
this.comparator = null;
initFromCollection(c);
}
}
private void initFromCollection(Collection<? extends E> c) {
initElementsFromCollection(c);
heapify();
}
private void heapify() {
final Object[] es = queue;
int n = size, i = (n >>> 1) - 1;
final Comparator<? super E> cmp;
if ((cmp = comparator) == null)
for (; i >= 0; i--)
siftDownComparable(i, (E) es[i], es, n);
else
for (; i >= 0; i--)
siftDownUsingComparator(i, (E) es[i], es, n, cmp);
}
}
정말 sift down 연산을 통해 heap을 생성하고 있다. heapify() 에 달린 설명에서도 시간복잡도가 O(N)임을 명시하고 있다.
Establishes the heap invariant (described above) in the entire tree, assuming nothing about the order of the elements prior to the call. This classic algorithm due to Floyd (1964) is known to be O(size).
정리
힙에 노드 추가 및 삭제는 O(logN)의 시간복잡도를 가진다.
하지만 기존 배열로 힙을 생성하는 경우 sift down 연산을 사용하면 O(N)의 시간복잡도를 가져 효율적으로 생성할 수 있다.